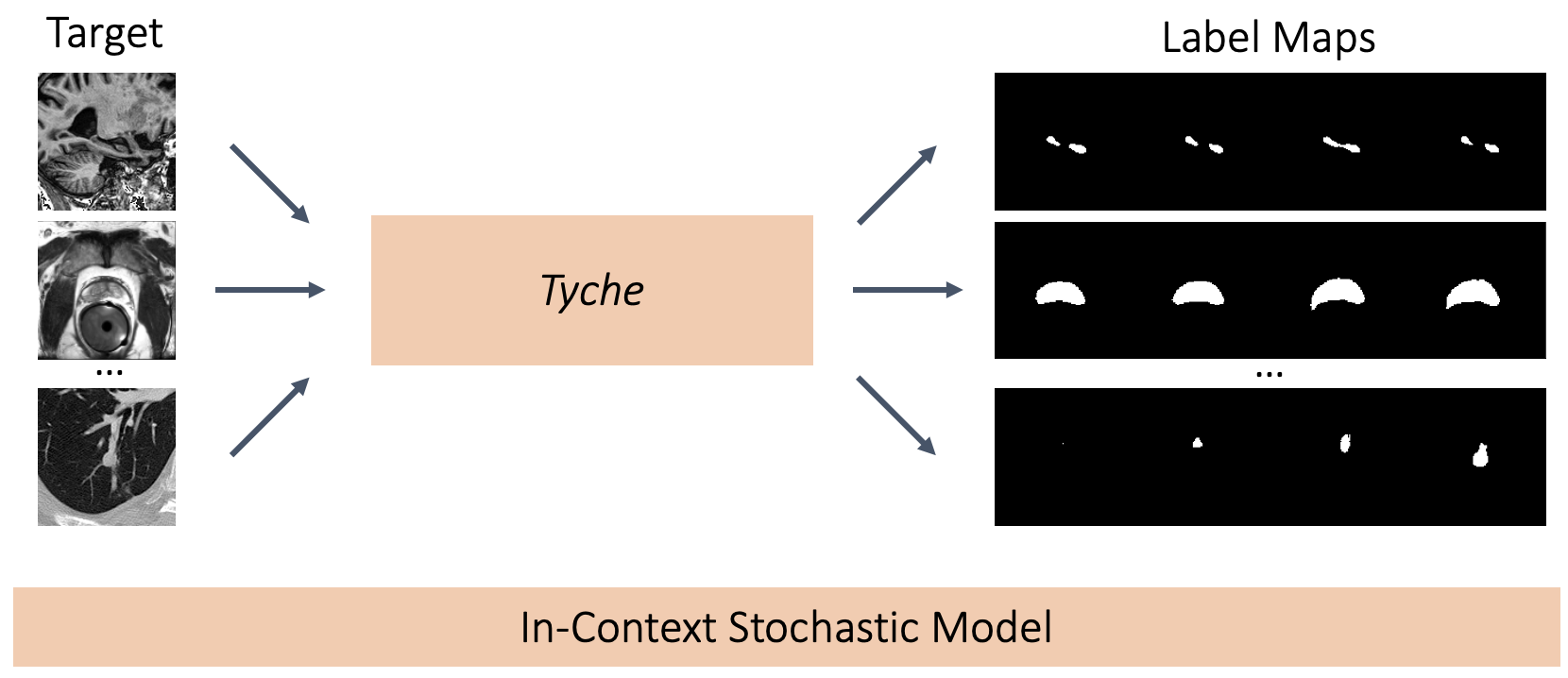
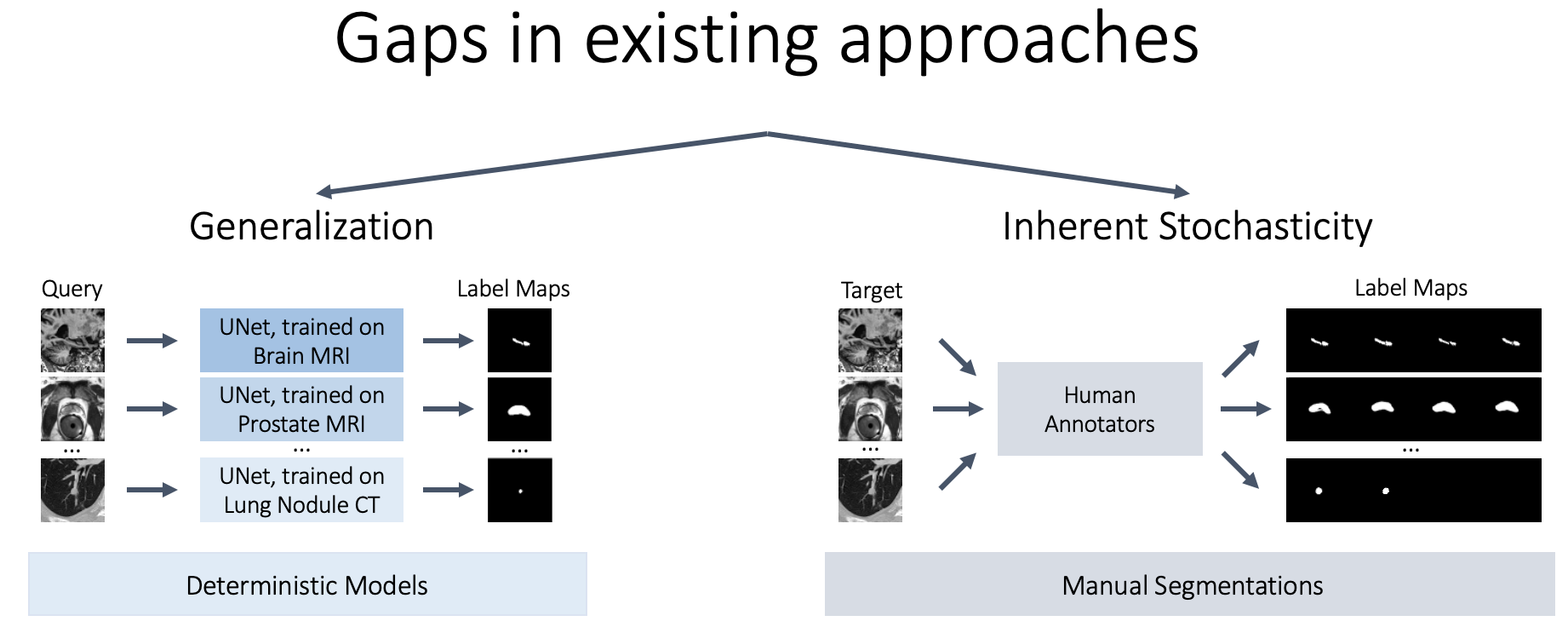
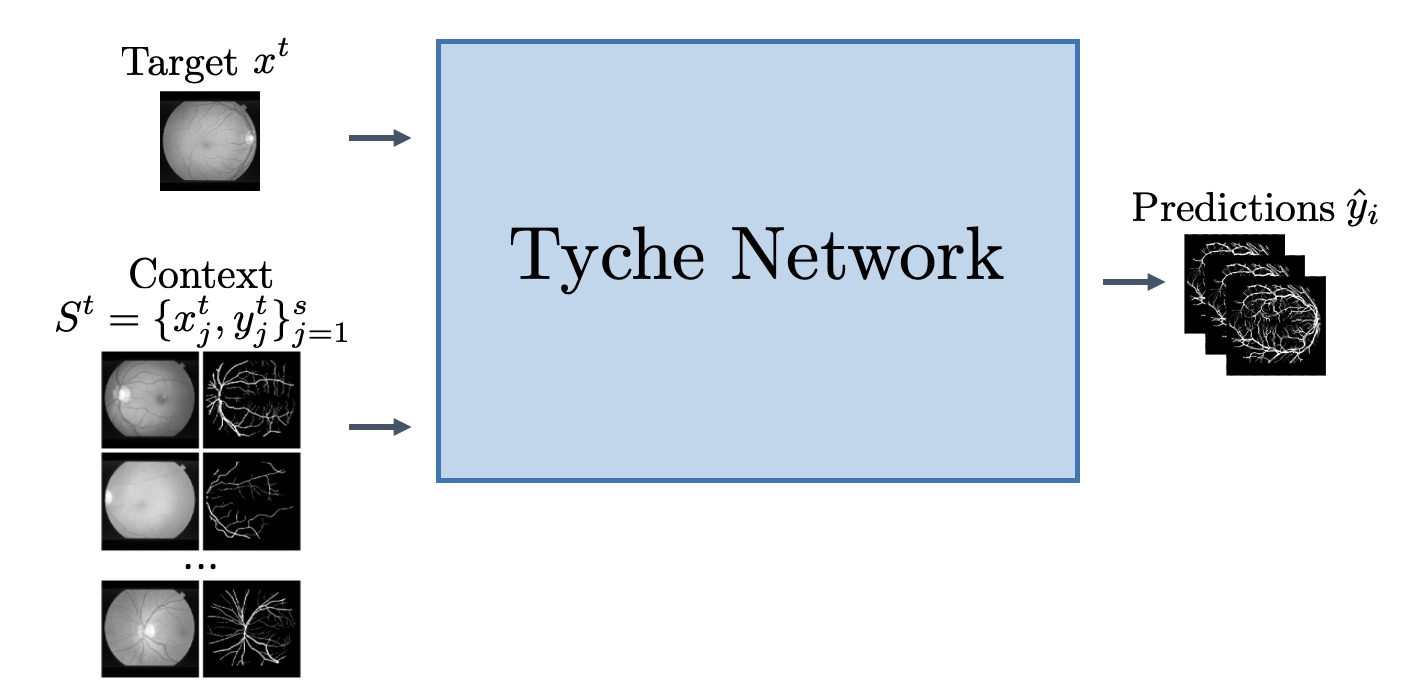
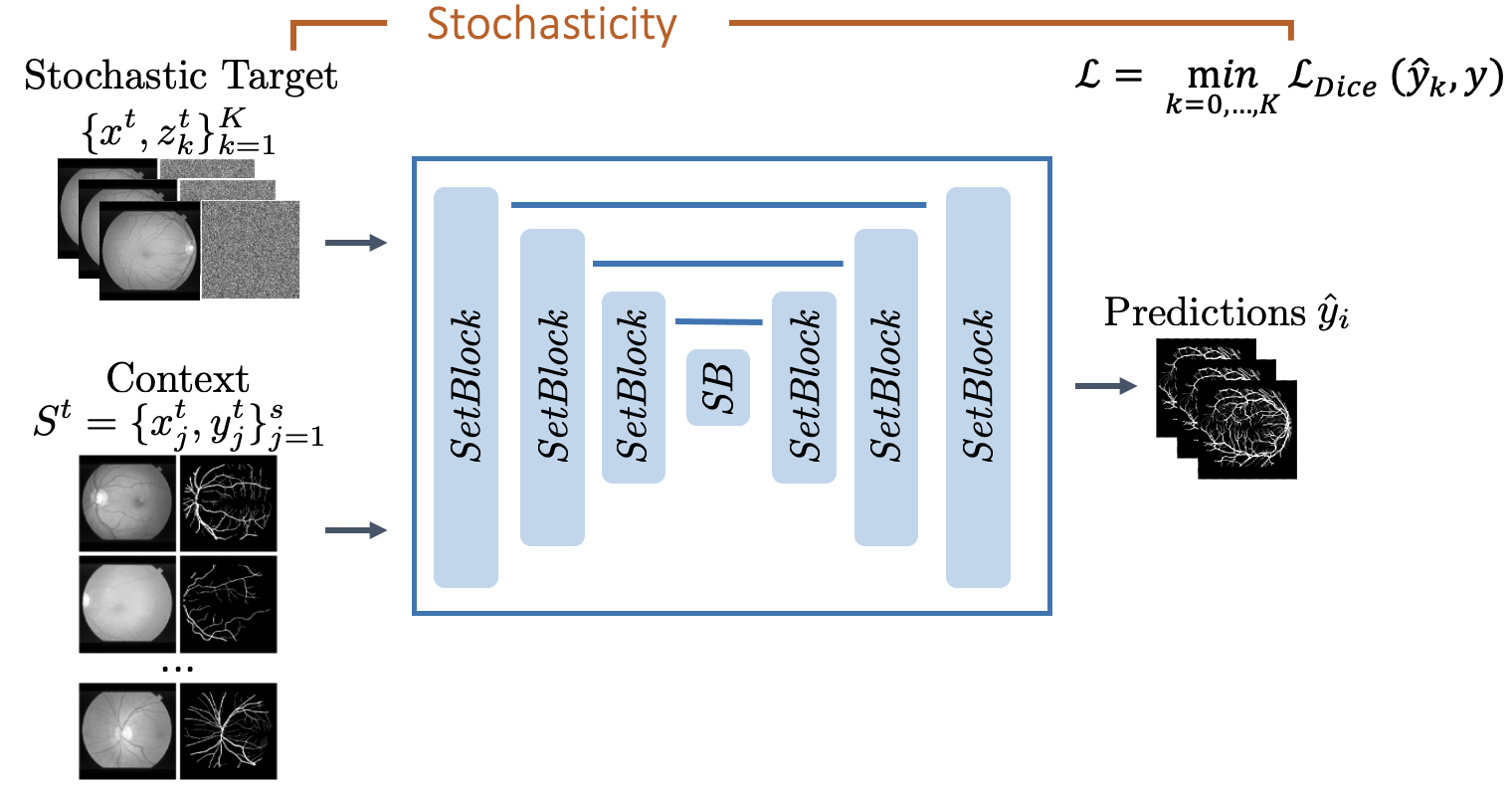
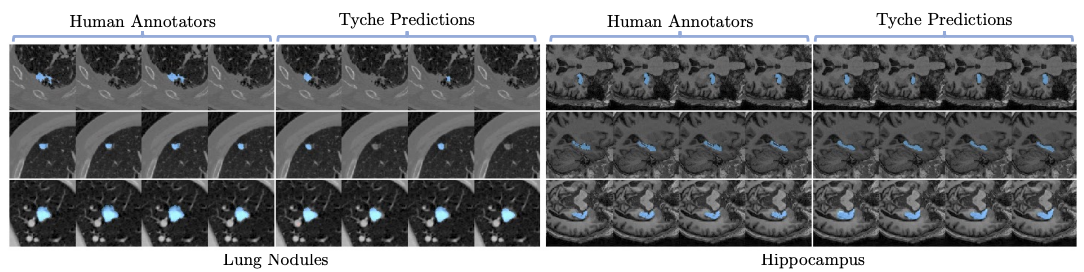
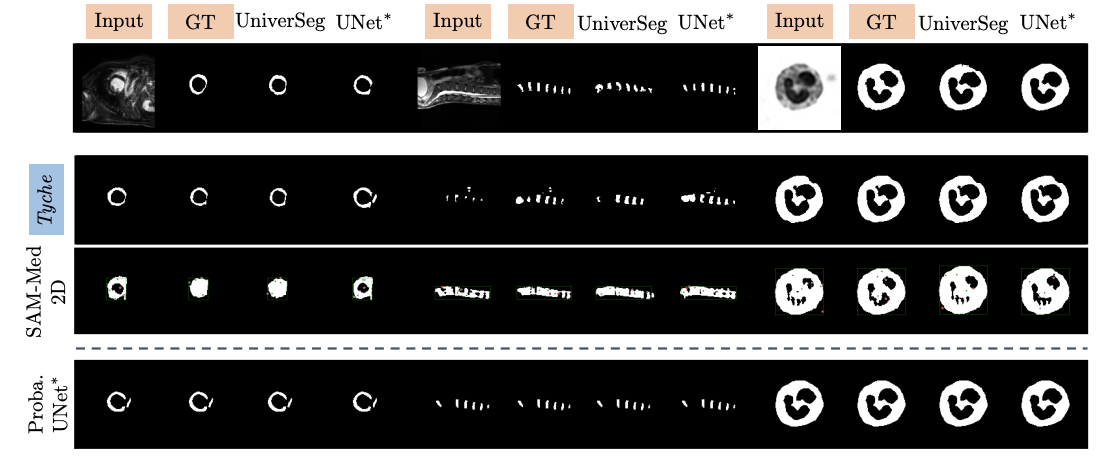
Overview
We present Tyche, a stochastic strategy for in-context medical image segmentation, to both generalize to new tasks and capture uncertainty
Tyche produces multiple candidate segmentations for images from unseen biomedical datasets without retraining fine-tuning